


Definition :
SAP Data Tiering and Archiving Strategies: Data Tiering allows you to assign data to various storage areas and storage media. The critera for this decision are data type, operational considerations, performance requirements, frequency of access, and security requirements.
Data Tiering (SAP Data Tiering and Archiving Strategies)
Data Tiering allows you to assign data to various storage areas and storage media. The critera for this decision are data type, operational considerations, performance requirements, frequency of access, and security requirements.
Customers often employ a multi-temperature or data tiering storage strategy, with data classified depending on frequency of access and certain other criteria as either hot, warm or cold. Depending on this classification, the data is kept in different storage areas or media.
Data tiering can be required for various reasons. For example:
- Storage of historical data
- Storage of mass data (settlement data, automatic logs, clickstream data) but restricted capacity on your SAP HANA database
- Guidelines for saving company data, such as the need to save all data for at least seven years in order to comply with legal requirements.
In addition to frequently accessed active data, large SAP BW∕4HANA systems also contain a large volume of data that is only accessed rarely. The data is either never or rarely needed in Data Warehouse processes or for analysis. The main challenge of implementing a data tiering strategy is to seamlessly integrate the warm and cold memory areas and to make these areas invisible to the outside, in order to ensure that all required functions are applied to this data. SAP provides data tiering solutions for this, helping to reduce TCO thanks to optimized SAP HANA main memory resource management.
The following graphic provides an overview of multi-temperature data classification and the storage areas available for the various data categories:

The following solutions are available in SAP BW∕4HANA for data tiering.
Data Tiering Optimization (DTO)
Data Tiering Optimization (DTO) is the strategic solution for data tiering in SAP BW∕4HANA. It offers the following advantages:
- A single data tiering solution for hot data (hot store in SAP HANA), warm data (warm store in SAP HANA Extension Nodes or SAP HANA Native Storage Extension) and cold data (cold store in SAP IQ)
- Central definition of the data temperature based on partitions of the DataStore object
- Movement of the data to the dedicated storage location as a simple and periodically performed housekeeping activity (TCO reduction)
- Smooth co-existence of Data Tiering Optimization and the existing near-line storage approach, as the same technical concepts are used for the storage areas for cold data, such as locking archived data
Near-Line Storage
Near-line storage (with no DTO support) with SAP IQ is still supported in SAP BW∕4HANA. This provides you with:
- Continuity for data archiving scenarios that are already implemented with near-line storage with SAP IQ before SAP BW∕4HANA Data Tiering Optimization is introduced SAP Data Tiering and Archiving Strategies
- Support for more complex data archiving scenarios that are not covered by SAP BW∕4HANA Data Tiering Optimization
Data Archiving for SAP Business Planning and Consolidation 11.0, version for SAP BW/4HANA :
System performance may be affected by large data storage
without proper data aging strategy in place. In order to reduce administration costs and efforts, optimize system performance, we advise to implement data archiving processes.
This will help classify data according based on Information Lifecycle Management recommendations.
Knowing how current data can be archived , stored in near-line storage, can really improve performance.
Data archiving keeps data constant and consistent without deletion.
The data is first moved to an archive or near-line storage and then deleted from the SAP BW/4HANA system. Data can be either directly accessed or loaded back for reporting purposes.
Note that you should not change a near-line storage connection if it is being used in an active data archiving process.
Prerequisites
- Data have been loaded in InfoProvider
- Prior to archiving, Data must be activated before if using aDSO (Advanced Data Store Object)
- aDSO should not include non cumulative key figures and one of the modeling properties has to be selected
- fields length of aDSO is restricted to 18 characters maximum
Three (3) main Process Flows to be considered when running Data Archiving :
- Setup Data Archiving Processes:
- Scheduling Data Archiving Processes Using Process Chains:
- Manual request processing: Creating and Executing Archiving Requests:
Each data archiving process is assigned to one specific InfoProvider and has always the same name as this InfoProvider. Before scheduling a Data Archiving process using Process Chain, Data Archiving process has to be previously setup. Once Data Archiving process has been created and setup for an InfoProvider, you may manually setup, launch , reload archiving request without using Process Chains. SAP Data Tiering and Archiving Strategies
Using a Data Transfer Process, InfoProvider data that has been archived using a data archiving process, can be loaded into other InfoProviders.
All data storage features can be configured using Data Tiering Optimization (DTO).
Data Tiering Optimization helps classify the data in the defined DataStore object (advanced) as hot, warm or cold, depending on how frequently it is accessed.
Data Tiering Optimization job moves the data to the corresponding storage areas at regular intervals

We consider following options within DTO interface :
- Standard Tier (hot): The data is stored in SAP HANA.
- Extension Tier (warm): The data is stored in a SAP HANA extension node.
- External Tier (cold): The data is stored externally (in SAP IQ).
* Note that Hadoop-based external storage is currently only possible via SAP NLS data archiving processes and not via DTO.

Both Standard and Extension Tier built a Logical Unit for high availability whereas External Tier is managed separately.Using External Tier , Data are stored in external storage (NLS: Near-Line Storage Solution) in either SAP IQ or HADOOP.
- Configuring SAP IQ as a Near-Line Storage Solution.For more information, see SAP Note 1737415 Information published on SAP site and SAP Note 1796393 .
- Configuring Hadoop as a Near-Line Storage Solution. For more information on prerequisites, recommendations and restrictions, see SAP Note 2363218.
Editing and customizing aDSO with NLS (Near Line Storage) :
- Run Transaction Code RSDAP to start editing built Advanced DataStore Object (aDSO)
- Select Edit and Select your defined NLS Connection (Near-Line Storage connection) under the “General Settings” ta

Click on ” Selection Profile ” to include “Primary Partition Characteristic” definitions based on archiving strategy.
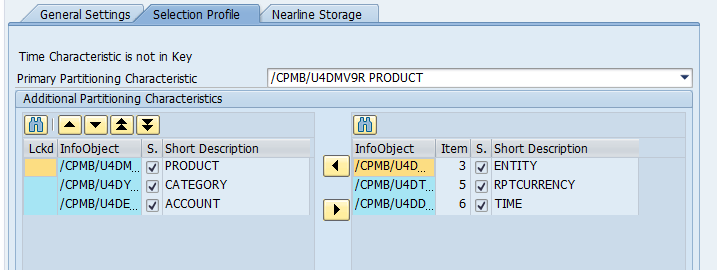
Under ” Nearline Storage “, define maximum Size , number of Data Objects for NLS and make sure the associated Near-Line Object and Near-Line connection are selected before saving the changes.

Note: Edit Data Archiving Process with transaction code RSDAP
For DataStore objects (advanced), data archiving process is used in near-line storage . Storing historical data in near-line storage reduces the data volume of InfoProviders, but the data is still available for queries. The database partitions and the near-line storage partitions for an InfoProvider consistently reflect the total dataset.
In BW/4HANA, BPC (Standard) Time and any other BPC Dimensions can be included in the Data Archiving process. Before BW /4HANA , only BW Time Characteristics could be used in a Data Archiving process (this was not applicable to BPC).
Conclusion :
In conclusion, SAP Data Tiering and Archiving Strategies offer a holistic approach to data management, optimizing performance, and ensuring compliance. By carefully implementing these strategies and learning from industry best practices, organizations can unlock the full potential of their SAP systems.
FAQs
- What is the primary goal of SAP Data Tiering?
- The primary goal is to optimize storage and access costs by categorizing data based on usage patterns.
- How does archiving contribute to improved SAP system performance?
- Archiving removes infrequently accessed data from the active database, reducing its size and enhancing system performance.
- What challenges are commonly faced in SAP data tiering and archiving?
- Challenges may include data migration complexities, system compatibility issues, and resistance to change.
- Why is the integration of data tiering and archiving crucial?
- Integration ensures a comprehensive data management strategy, aligning data storage with access patterns.
- What are the key components of SAP data tiering?
- The key components include hot data (frequently accessed), warm data (less frequently accessed), and cold data (rarely accessed).



![Pop Up Debugging [ROBO 2.0]](https://technicalgyanguru.com/wp-content/uploads/2025/05/ABAP-for-SAP-HANA.-ALV-Report-On-SAP-HANA-–-Opportunities-And-Challenges-3.png)

